Conversational BI: the art of querying Databases in Natural Language
Debmalya Biswas
AI/Analytics @ Wipro | x- Nokia, SAP, Oracle | 50+ patents | PhD - INRIA
Introduction
“Future of BI is Conversational” — this is what industry analysts and experts have been telling us for the last few years.
Let’s focus on structured data, relational data to be precise. This forms the underlying storage format for most of the Business Intelligence (BI) world, irrespective of whether you are querying the database interactively or building a report in Tableau, Power BI, Qlik Sense, etc. The predominant language to interact with such storage platforms is SQL. We have already seen some products in this space, e.g., Power BI Q&A, Salesforce Photon.
We are talking about translating a Natural Language Query (NLQ) to SQL in this article, also known as a Natural Language Interface to Databases (NLIDB).
For example, let us consider a Country table with Language and Population details — illustrative schema below:
Country table: Country ID | Name | Language | Population Count
NLQ1: Which country has the maximum population count?
SQL1: Select Name, max([Population Count]) from Country;
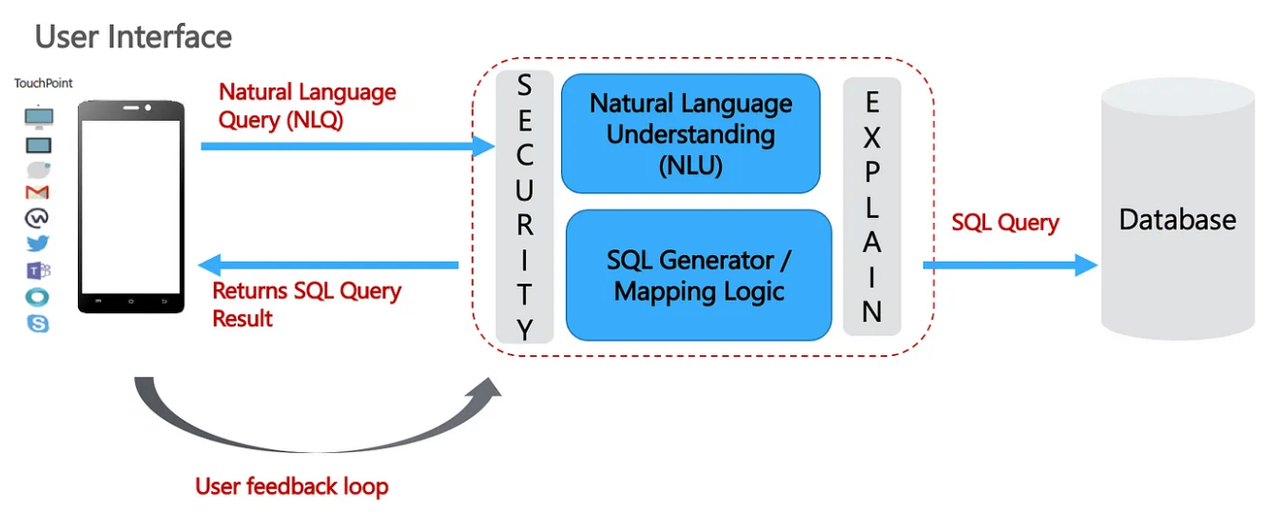
At the core of most Natural Language Q&A systems [1] - illustrated in Fig. 1, is a Natural Language Understanding Unit (NLU) module that is trying to understand the NLQ’s intent by extracting and classifying the ‘utterances’. In simple words, one can think of utterances as the key phrases in the sentence, e.g., country, maximum, population, count.
The next step is to generate the corresponding SQL query based on this information. So we need a transformation / mapping logic to map ‘country’ to the ‘Country’ table (the table to be queried), ‘maximum’ to the MAX SQL function, ‘population count’ to the column ‘Population Count’. And, this is where things start to get challenging.
The two steps can be considered as the encoder-decoder layers of a Transformer neural network architecture.
Mapping NLQ utterances to the right SQL operators, esp., in determining if an utterance corresponds to a Table, Column, Primary / Foreign Key, SQL operator, in the first place —is non-trivial.
For example, without any inherent knowledge of the database schema, it is very difficult for the mapping logic to determine that the ‘count’ in this case refers to the column ‘population count’ , and not the SQL function COUNT. The problem gets amplified for complex queries, e.g.,
NLQ2: Which language is spoken by maximum number of countries?
whose SQL translation would involve both the SQL functions: MAX & COUNT. Other examples of complex queries include scenarios where we need to JOIN multiple tables.
NLQ — SQL translation Deep Dive
In this section, we do do a deep dive into the problem domain, reflecting on existing literature / approaches — to understand the technical challenges involved.
There are two benchmark datasets that are primarily referenced in this field:
WikiSQL: is a large annotated corpus for developing natural language interfaces, which was introduced along with the paper [2].
Spider is a large-scale annotated semantic parsing and text-to-SQL dataset. SParC is the context-dependent/multi-turn version of Spider, and CoSQL is the dialogue version of Spider and SParC datasets. For a detailed discussion, refer to the accompanying paper [3].
As Spider highlights in its introductory text, any NLIDB solution needs to not only understand the underlying database schema, but it should generalize to new schemas as well. The generalization challenge lies in (a) encoding the database schema for the semantic parser, and (b) modeling alignment between database columns, keys, and their mentions in a given NLQ [4].
With this context, let us take a look at some works that have tried to encode (the missing) database schema knowledge into neural networks. Directed graphs are a popular formalism to encode database schema relationships.[4] presents a unified framework to address schema encoding, linking, and feature representation within a text-to-SQL encoder. [5] encodes the database schema with a graph neural network, and this representation is used at both encoding and decoding time in an encoder-decoder semantic parser. [6] presents a database schema interaction graph encoder to utilize historical information of database schema items. In the decoding phase, a gate mechanism is used to to weigh the importance of different vocabularies and then make a prediction of SQL tokens.
Pre-trained large language models [7] as text-to-SQL generators help to a certain extent, esp., with respect to encoding table and column names by taking advantage of the attention mechanism [8]. However, they still struggle with schema relationships for complex SQL operation.
The papers show significant progress in embedding database schemas, however, they are still specific to the datasets under consideration; and do not generalize well to new domains / schemas.
Solution Pointers
In this section, we consider approaches to best add this missing domain knowledge / database schema relationships to a text-to-SQL generator.
Encoding domain (schema) knoweldge via Knowledge Graphs
The majority of Q&A systems today consist of a Natural Language Understanding (NLU) unit trained to recognize the user’s query in a supervised manner. Domain knowledge can be added in the form of ‘entities’ [9], e.g., they can refer to the office locations of an organization, in the context of an HR app.
The point here is that similar to fine-tuning LLMs, we can also enter the domain knowledge - natural language representation of the database schema in this case - in the form of say embeddings / knowledge graphs to improve the text-to-SQL generation in NLIDB systems.
To clarify, a SQL parser can extract the table, column names, key relationships, etc., from the underlying Data Definition Language (DDL) specification file.
So the additional domain knowledge that needs to be encoded in this case is the natural language description of tables, columns, and their relationships — which is missing from most database documentations.
While this encoding / fine-tuning helps, and is often the most reliable approach; it is important to understand that NLIDB systems are primarily intended for business users, who may not be the most suited to maintain knowledge graphs in a continuous manner. (This is not one-time tuning, and the encoded domain knowledge will need to be adapted every time the underlying database schema changes.)
Automated approaches based on Active / Reinforcement Learning
A good way to bootstrap text-to-SQL generators is by learning from existing SQL query logs and BI reports. It is fair to say that most NLIDB systems will complement existing BI platforms. So it makes sense to leverage historical SQL logs and existing reports / dashboards to get an understanding of the most frequently asked SQL queries, and consequently the NLQs that can be used for initial training.
The generalization ability of this initial model can be improved by introducing an auxiliary task, which can explicitly learn the mapping between entities in the NLQ and table, column, key names in the schema [10]. Recent works have extended this to few shot learning tasks, e.g., [11] proposes an efficient meta-learning strategy that utilizes a two-step gradient update to force the model to learn a generalization ability towards zero-shot tables.
Reinforcement Learning (RL) approaches are also interesting in this context, where a Deep Q-Network (DQN) agent can be trained to ‘score’ novel (unseen) queries, such that they can be effectively added to augment the (offline) training dataset. For instance, [12] proposes a RL based self-improving enterprise chatbot that shows an increase in performance from an initial 50% success rate to 75% in 20–30 training epochs.

Conclusion
We conclude with some thoughts for the future. With text-to-SQL, the main goal has been to recreate the SQL querying to databases paradigm, to one using Natural Language Queries (NLQs).
We believe that Conversational BI will be far more disruptive, in enabling new ways of interacting with databases (or data stores in general).
For instance:
Metadata Bot: Given the complexity of enterprise databases, and the subsequent difficulty in encoding them; may be we have been approaching the problem wrongly to start them. If we can provide the users with a Q&A system (let’s call it Meta Bot — meta as in metadata queries, and nothing to do with Meta / Facebook) that can answer queries reg. the database schema, e.g., ‘Which table contains the Sales data for Switzerland?’ together with some sort of auto-complete for SQL operators, e.g., ‘Do we have the Sales Data for Germany and Spain in one table?’, answered by a join / filter on the respective table(s); the users will be able to compose their SQL queries efficiently, without the need for any advanced SQL knowledge.
Incremental queries: The previous point already alludes to it. Queries today are mostly one-shot. Our conversations on the other hand have a flow — we continue what has been said before — based on historical context [13]. Yes, a stored procedure performs SQL queries in sequence, however, it is pre-defined logic. Conversational BI would enable incrementally refining the query results in real-time, until the user finds the data that that he / she is looking for in real-time.

References
D. Biswas. Chatbots & Natural Language Search. Towards Data Science, https://towardsdatascience.com/chatbots-natural-language-search-cc097f671b2b
Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning. https://arxiv.org/abs/1709.00103
Tao Yu, et al. 2018. Spider: A large-scale Human-labeled Dataset for Complex and Cross-domain Semantic Parsing and Text-to-Sql Task. https://arxiv.org/abs/1809.08887
Bailin Wang, et. al. 2020. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. In Proc. of the 58th Annual Meeting of the Association for Computational Linguistics. https://doi.org/10.18653/v1/ 2020.acl-main.677
Ben Bogin, Matt Gardner, Jonathan Berant (2019). Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing. ACL, https://arxiv.org/pdf/1905.06241.pdf
Yitao Cai and Xiaojun Wan. 2020. IGSQL: Database Schema Interaction Graph Based Neural Model for Context-Dependent Text-to-SQL Generation. In Proc. of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), https://aclanthology.org/2020.emnlp-main.560.pdf
Lin, X.V., Socher, R., & Xiong, C. (2020). Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing. FINDINGS. https://arxiv.org/abs/2012.12627
Bahdanau, Dzmitry, Kyunghyun Cho and Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. https://arxiv.org/pdf/1409.0473.pdf
W. Shalaby, A. Arantes, T. G. Diaz, and C. Gupta. Building chatbots from large scale domain-specific knowledge bases: Challenges and opportunities, 2020, https://arxiv.org/pdf/2001.00100.pdf
Chang, S., Liu, P., Tang, Y., Huang, J., He, X., & Zhou, B. (2020). Zero-shot Text-to-SQL Learning with Auxiliary Task. AAAI, https://arxiv.org/pdf/1908.11052.pdf
Chen, Y., Guo, X., Wang, C., Qiu, J., Qi, G., Wang, M., & Li, H. (2021). Leveraging Table Content for Zero-shot Text-to-SQL with Meta-Learning. AAAI, https://arxiv.org/pdf/2109.05395.pdf
E. Ricciardelli, D. Biswas. Self-improving Chatbots based on Reinforcement Learning. 4th Multidisciplinary Conference on Reinforcement Learning and Decision Making (RLDM), 2019, https://towardsdatascience.com/self-improving-chatbots-based-on-reinforcement-learning-75cca62debce
S. Reddy, D. Chen, C. D. Manning. CoQA: A Conversational Question Answering Challenge. Transactions of the Association for Computational Linguistics 2019, https://doi.org/10.1162/tacl_a_00266
Builder @ Waii
3moWith Microsoft, we (Waii) wrote about this as well, just published in CIDR - https://www.cidrdb.org/cidr2024/papers/p74-floratou.pdf. We here at Waii are committed to delivering an enterprise text-to-SQL API with the most complete and accurate translation of plain English to SQL available.
Developer at Dynosi Government Services
10moThis is exactly what I want, but I have to wonder how well it works with real-world schemas -- schemas with dozens, if not hundreds, of tables where the queries entail lots of joins. Have you tried this with complicated database schemas? Does it work?
Head of Pega Practice at LTI India
1yDon't you think we are making multiple wrappers of conversations. What benefits it will give for any organisation
Data Analytics at American Electric Power
1yThank you for sharing Biswas
Senior Director - Data & Intelligence at Mindtree
1yVery informative article … Superb one …